
Data warehousing as a concept had its origins in the 1980s when organizations started building warehousing solutions for business data. A data warehouse is a centralized storage and processing system for organizational data coming from a multiple sources. They enable organizations to make more informed decisions about business through data collection, consolidation, analytics and research.
Evolution of new data forms
Since the inception of data warehousing, a lot of things have changed. Due to the amount and diversity of data generated by businesses, data warehouses require more storage, networking, computing and memory. As organizations expand their customer base and embrace new technologies, the amount of enterprise data generated is growing exponentially. This is not limited to structured data and includes sensor data, network logs, video feeds, audios feeds, social media feeds and other unstructured data.
Another major shift that has occurred, is the way enterprise data is consumed. Analyzing data helps an organization to improve products, build intelligent models, and execute targeted marketing campaigns and predictive modeling. This is paving the way for democratization of data within organizations given that proper security, governance and compliance controls are in place.
Traditional Data Warehouses
Are data management systems established inside enterprises for analytics and reporting, which act as the core component for enabling business intelligence within an enterprise. A typical enterprise data warehouse includes major components like an ETL layer to ingest and transform the data, a relational database for storing the transformed data, and tools for analytics, reporting and visualization.
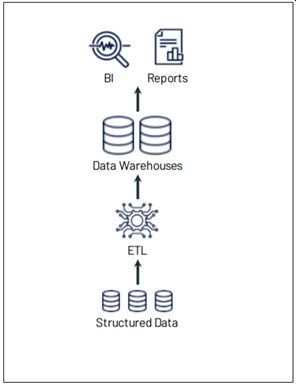
The effectiveness and flexibility of any data management system largely depends on the data model used for storage. Traditional data warehousing systems use a ‘Schema-On-Write’ data model; which is structured and forces the incoming data to fit into a pre-defined format. This is a major bottleneck for dealing with heterogeneous data and emerging consumption patterns for data within enterprises. Therefore new approaches in data warehousing which can handle diverse data with high volume from various enterprise systems are the need of the hour.
Data lakes
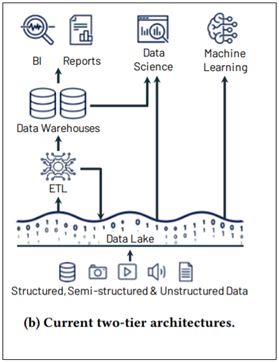
A Data lake enables organizations to store and consume diverse enterprise data to make informed business decisions. The fundamental concept of a data lake is to establish a single source of truth inside the organization for decision making. A data lake is a vast pool of raw enterprise data whose consumption patterns or reasons are yet to be defined.
Data lakes do not impose any rigid schema on the data ingested from various sources; they enable the physical and logical separation of data. They encourage a ‘Schema-On-Read’ policy rather than a ‘Schema-On-Write’ policy of traditional data warehouses. The flexibility in ingesting large volumes enterprise data enables organizations to collect and store data and derive insights at a later point in time.
Some fundamental design principles in a modern data lake include:
Even though data lakes have brought in a revolutionary change into the enterprise data warehousing approach, handling raw data using data lakes comes with its own challenges as under:
Lakehouses
Lakehouses combine the best elements of data warehouses and data lakes, and seamlessly support data consumption for business intelligence, reporting, data science, data engineering, machine learning and artificial intelligence. Lakehouses follow an architecture which implements a similar structure and management approach of a data warehouse but uses a low cost cloud storage, open format of a data lake.
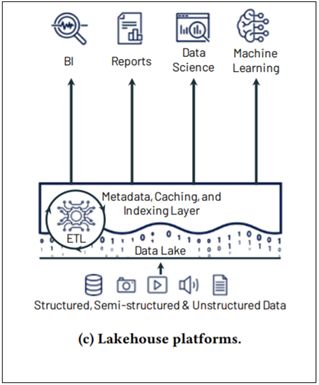
The Databrick’s lakehouse for example introduces a storage layer which brings reliability to data lakes. It is an open source storage layer which provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Other features of Delta Lake include:
Lakehouses also support features like decoupled storage and compute, open and standardized storage formats (like parquet), support for structured and unstructured data, indexing, support for diverse workloads like data science, machine learning, SQL and analytics. This makes data consumption more efficient, reliable and effective.
What the future holds
As data sources and types continue to proliferate, development of hyper-scale data warehouses with robust computing power and high storage capacities will become critical. The integration of cloud computing technologies into data warehousing and the availability of affordable big data solutions will continue to disrupt the way enterprises leverage data analytics. By partnering with organizations like Quest Global, customers can navigate data complexity, benefit from end-to-end data engineering and analytics across verticals, choose the right approach and accelerate data intelligence transformation.
References:
https://databricks.com/research/lakehouse-a-new-generation-of-open-platforms-that-unify-data-warehousing-and-advanced-analytics
https://databricks.com/discover/pages/the-rise-of-the-lakehouse-paradigm
https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
https://docs.microsoft.com/en-us/azure/databricks/
https://aws.amazon.com/blogs/big-data/build-a-lake-house-architecture-on-aws/

We are Quest Global. We’re in the business of engineering, but what we’re really building is a brighter future. It’s not just what we do, but why we do it that makes us different. We believe engineering has the unique opportunity to solve the problems of today that stand in the way of tomorrow. For more than 25 years, we have strived to be the most trusted partner for the world’s hardest engineering problems. As a global organization headquartered in Singapore, we live and work in 17 countries, with 67 global delivery centers and offices, driven by 17,500+ extraordinary employees who make the impossible possible every day.
Quest Global delivers world-class end-to-end engineering solutions by leveraging our deep industry knowledge and digital expertise. By bringing together technologies and industries, alongside the contributions of diverse individuals and their areas of expertise, we are able to solve problems better, faster. This multi-dimensional approach enables us to solve the most critical and large-scale challenges across the aerospace & defence, automotive, energy, hi-tech, healthcare, medical devices, rail and semiconductor industries.